From spreadsheet to website: doing DevOps on the N64 blog
A couple of colleagues of mine, Martin and Ash, have recently soft-launched a new blog for all things N64. I’ve been helping with some of the content management in a kind of supporting DevOps role. I thought it would be worth talking a little bit about this and plugging their new blog.
What’s “N64”?
The Nintendo 64 (N64) is a classic gaming console. It was released in 1996 and many who were gaming teens in the 1990s will have happy memories of playing such games as GoldenEye 007 (based on the eponymous James Bond film), Legend of Zelda: Ocarina of Time, and Mario Kart 64.
Both Martin and Ash are still keen players of the N64. They love it so much they wanted to create a site dedicated to it. So they did.
What’s “DevOps”?
Development operations (DevOps) is set of practices aimed at increasing a beneficial intersection between programming and development activities, operations – like writing content or managing data flows – and quality assurance.
It’s the way I’ve increasingly come to describe my role at work and I’ve come to realise it’s an interest I’ve been pursuing in my own time, with the gradual development of my own blog and my general interest in managing data and information.
I was interested to see if it would work in a different situation, albeit on a relatively small scale.
Game pages
Martin and Ash had already set up and launched the blog when I got involved. Martin had worked on content for several posts and Ash had worked up an initial design with feature blocks to change periodically as new key posts were added.
However, what they also wanted was to provide a catalogue of pages about all the games ever produced for the N64. There were 388 official game releases for the N64 so this is a manageable amount.
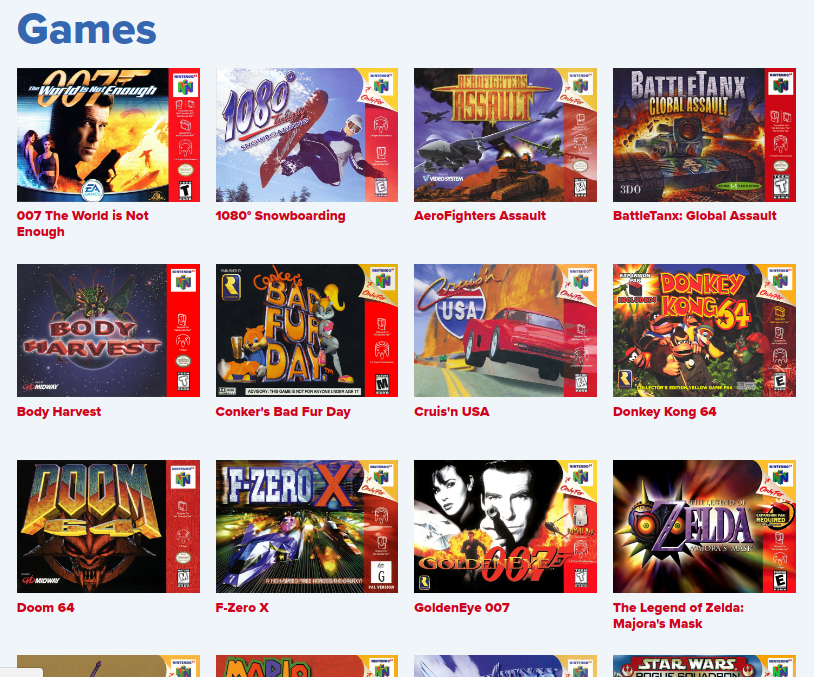
Creating a catalogue
The blog is based, like mine, on the Jekyll blogging platform using a GitHub pages for hosting. You can read my post on how I’ve used Jekyll and Github pages for this blog.
Originally, the game pages were set up manually as a series of Markdown files in the blog’s repository. However, with the need to fill out multiple details in the YAML frontmatter of those pages, Martin set up a spreadsheet with different columns for each field including the main content of each page, namely a description of the game.
When discussing this new approach with Martin at work, I said it would be possible to write a script that took the contents of this script and generated all the pages needed automatically. Martin was interested so I decided to go ahead and write it.
The technical bit
Martin’s spreadsheet was set up on Google Drive so that it was easy for Ash and me to see and, if needed, contribute to.
There were columns for the filename for each game, the meta data, various facts about the game (like year of release in each country) and even the associated asset file for the boxart which Ash was collecting. And, of course, a column for the content of the page itself.
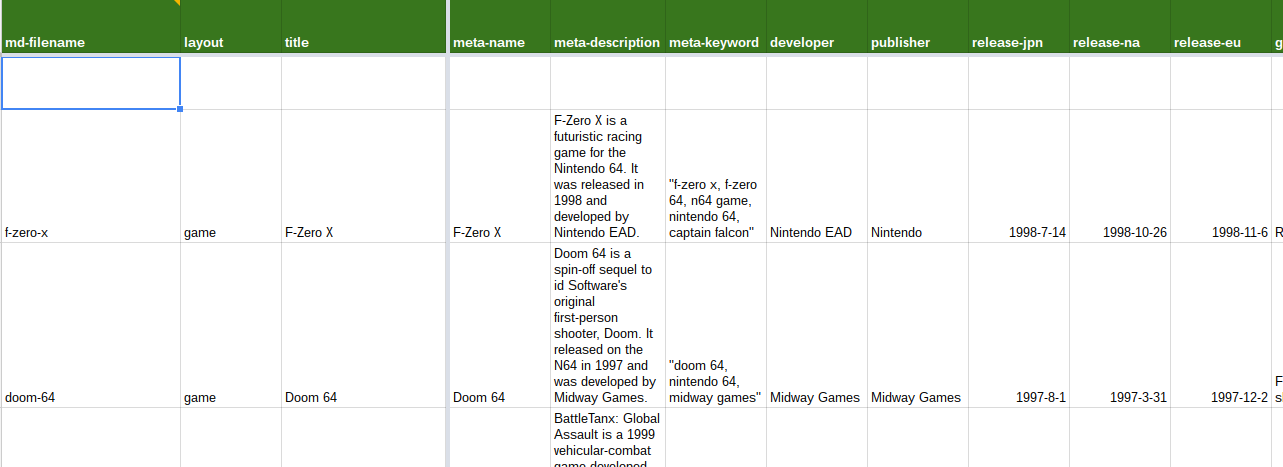
Writing the script itself was easy. We published the spreadsheet as a tab-separated value (.tsv) file to a public link and I was able to import and manipulate the data from there onwards.
Processing the data
I wrote the script for Node.js. The request to the spreadsheet is made via the https module.
There’s some standard error-handling of course, in case something has gone wrong at the Google Drive end. But, if all is well, the response is received and processed (here as res) via what I imagine is a fairly standard concatenation technique:
res.setEncoding("utf8")
var rawData = ""
res.on("data", (chunk) => rawData += chunk)
Once all data from the request has been collected as rawData, it’s split up:
- First, by line breaks to produce the different rows.
- Second, the header row is extracted and split up into header cells as its own array.
- Then, the other rows are individually split (by tab, of course) and each is assigned by its corresponding header to a data object.
- As long as there’s a filename (
md-filename) and description, the data object is then used to write the Markdown file for the gamepage.
Here’s the code.
res.on("end", () => {
try {
var rawArray = rawData.split(/ /)
var headers = (Array.isArray(rawArray) && rawArray[0])
? rawArray.shift().split(" ")
: null
if (headers) {
rawArray.forEach(row => {
var values = row.split(" ")
var data = {}
values.forEach((datum, index) => data[headers[index]] = datum)
if (data.hasOwnProperty("md-filename") && data["md-filename"] && data.hasOwnProperty("description") && data["description"]) {
data.description = data.description.replace(/\ \ /g, "
”) var fileContents = template(data) fs.writeFile(../_games/${data["md-filename"]}.md, fileContents, “utf8”, e => { if (e) throw e console.log(“Generated:”, data[“md-filename”]) }) } }) } } catch (e) { console.log(e.message) } })
Creating the pages
In the code above the function template is used on the object data for each row in the spreadsheet. That function is part of the Handlebars package, one of my favourite templating engines for Node.js.
The template itself is really quite simple – all the YAML matter is handled (if you’ll forgive the pun) with variables from the data object produced by the code above and then the description is throw in as an extra variable at the end.
---
layout: game
title: "{{title}}"
meta-name: "{{meta-name}}"
meta-description: "{{meta-description}}"
meta-keyword: {{{meta-keyword}}}
developer: {{developer}}
publisher: {{publisher}}
release-jpn: {{release-jpn}}
release-na: {{release-na}}
release-eu: {{release-eu}}
genre: {{genre}}
minplayers: {{minplayers}}
maxplayers: {{maxplayers}}
cartridge: {{cartridge}}
controllerpak: {{controllerpak}}
rumble: {{rumble}}
expansion: {{expansion}}
transfer: {{transfer}}
tags: {{tags}}
aka: "{{aka}}"
boxart: {{boxart-file-path}}
---
{{{description}}}
Is it really DevOps?
So I’ve set up a simple script for exporting the data from a spreadsheet and creating pages for each row. Is that really DevOps?
Perhaps not yet. But it could be.
Cultural shift
DevOps as I understand it is as much about a cultural shift as it is about the practice that that shift enables. The decision by Martin and Ash to use a spreadsheet to create their pages already showed a willingness, within an initially small website, to take on a more system-based mindset for managing the content and helping it grow.
I don’t know if I’ll continue to be involved now I’ve helped with this initial set up. I’m in the process of handing the script I’ve written over to them now.
But I can see the potential for more growth and planning in this way. Automating the committing of content to the blog rather than just the generation of pages is one way – a kind of continuous integration for content. Enabling better editing capabailities for the content is another.
Next
Go and check out the N64 blog!
Christmas season is almost upon us and I may not be blogging again for a week or two. And not just because of festivities and last-minute present-buying, unfortunately. I have a lot of other jobs on my list at the moment.
But I still have many posts lined up to write – including, potentially, some reviews of books I’ve been reading – and I’m looking forward to letting them out into the world in the New Year.