Using Atom Todo Show Package to check Markdown files
Whenever I write a post for this blog, I normally have a number of tasks I save until I’ve finished writing. Being in the writing flow, I don’t want to stop to look up a link or get the details of an image filename. However, when it comes to tidying up at the end, it’s hard to tell how much work there is left to do. I wanted a way of getting an overview of any outstanding post admin work I would need to do before I publish.
Links and images
I write my blog posts using Markdown.
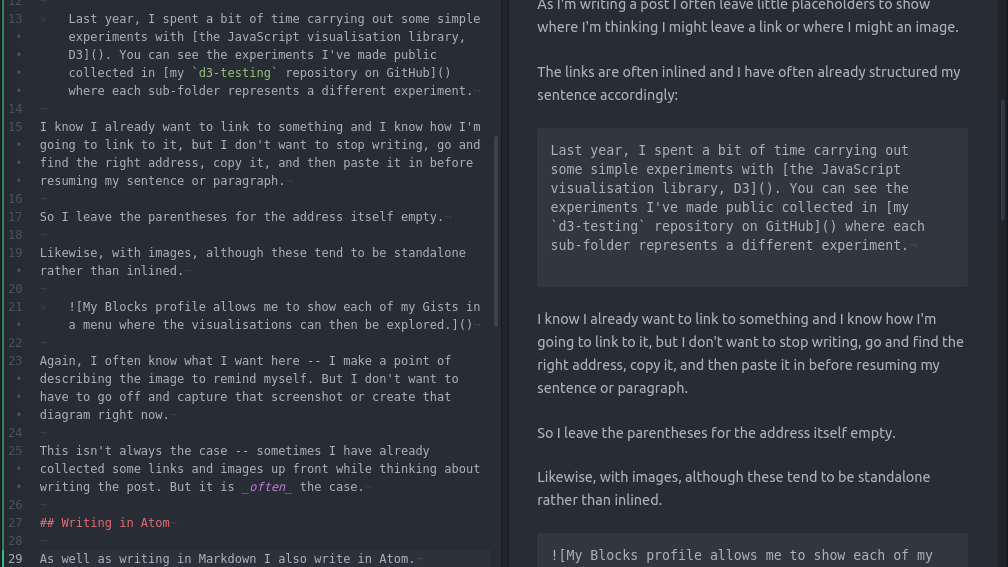
As I’m writing a post I often leave little placeholders to show where I’m thinking I might leave a link or where I might an image.
The links are often inlined and I have often already structured my sentence accordingly. For example:
Last year, I spent a bit of time carrying out some simple experiments with [the JavaScript visualisation library, D3]().
I know I already want to link to something (in this case, the D3 site) and I know how I’m going to link to it, but I don’t want to stop writing, go and find the right address, copy it, and then paste it in before resuming my sentence or paragraph.
So I leave the parentheses for the address itself empty.
Likewise, with images, although these tend to be standalone rather than inlined.
![My Blocks profile allows me to show each of my Gists in a menu where the visualisations can then be explored.]()
Again, I often know what I want here – I make a point of describing the image to remind myself. But I don’t want to have to go off and capture that screenshot or create that diagram right now.
This isn’t always the case – sometimes I have already collected some links and images up front while thinking about writing the post. But it is often the case.
Writing in Atom
As well as writing in Markdown I also write in Atom.
As with most text editors, I can hit Ctrl and f if I want to find instances of empty parentheses where I might still need to add images. That will even tell me how many images or links I still have left to fill out.
But one of the advantages of Atom is that it’s extensible and I became curious about whether there was a package out there that could help me make this tidying up process more efficient.
Existing packages
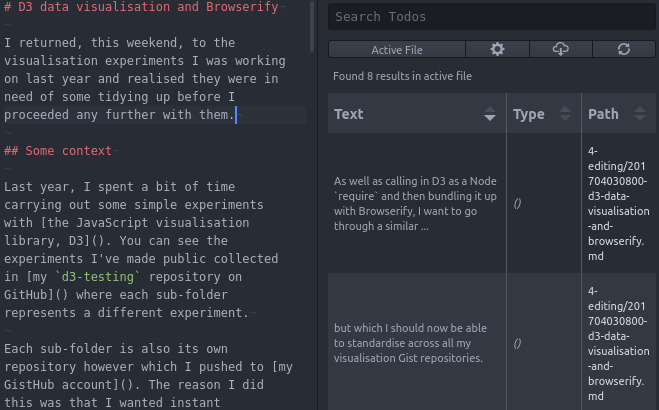
I couldn’t find anything that would do exactly what I wanted it to do – specifally a check list of how to tidy up my Markdown. But it didn’t take me a great deal of searching to find an Atom package called todo-show.
This package is primarily designed for working with code, where you might have left TODO, FIX or similar comments to pick up later. It finds instances of these and it generates an automatic list which can then be sorted and even downloaded.
The list can appear in a separate pane alongside your working document, much like the Markdown preview in Atom can.
I immediately knew I didn’t want to start dropping a load of TODO notes in my Markdown files. I could of course, but it should be evident from the fact that there are empty parentheses that there are things left to do in the file. What if I were to forget to add a TODO note somewhere?
No, I wanted the list to look for already existing symptoms of areas that needed fixing, much as a spell checker might.
Customising Todo Show
Luckily I found out that the Atom package todo-show has configuration options.
One can add an empty set of parentheses to the list of “todos” or task labels you want the package to find.
But that doesn’t give all the context you might need, such as, the terms of which link to find or which image to create or look for. This is a missed opportunity, given that all the information is already there. I’ve gone to the effort of describing what each link or image should or might be while I’m writing. If using todo-show is going to be better than a simple Ctrl and f search, it ought to give me at least as much information in one place.
Regex experimentation
Luckily, todo-show not only allows you to add to the array of possible TODO variations; it also allows you to change the regular expression pattern that it uses.
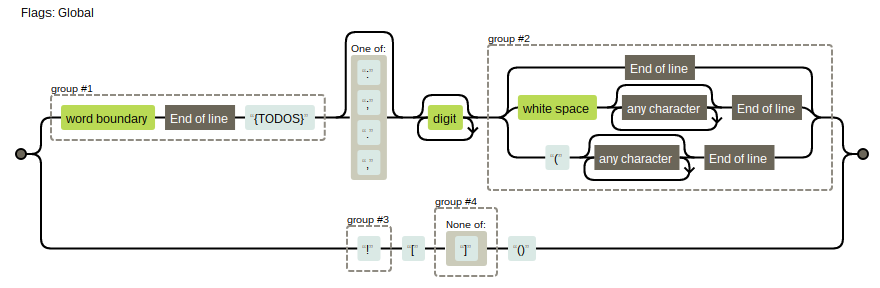
The default regex string is given as:
'/\b(${TODOS})[:;.,]?\d*($|\s.*$|\(.*$)/g'
The ${TODOS} part is replaced by the array of possible task labels (TODO, FIX, and so on) that I mentioned earlier.
Removing the quotation marks and the additional backslashes, one can get a visualisation of this using Regexr, an in-browser regex visualisation tool.
/(${TODOS})[:;.,]?\d*($|\s.*$|\(.*$)/g
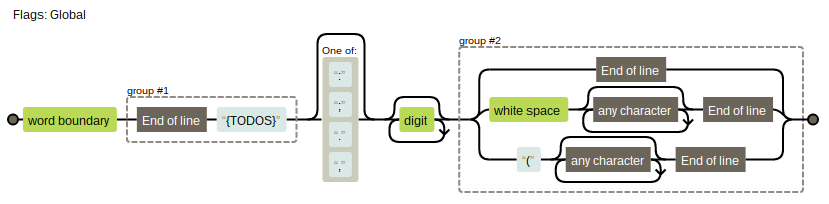
One can see that there are two capture groups in the regex pattern. One captures the type of task this is (normally whether the label captured is TODO or FIX or whatever). The other captures whatever text follows, presumably the task itself.
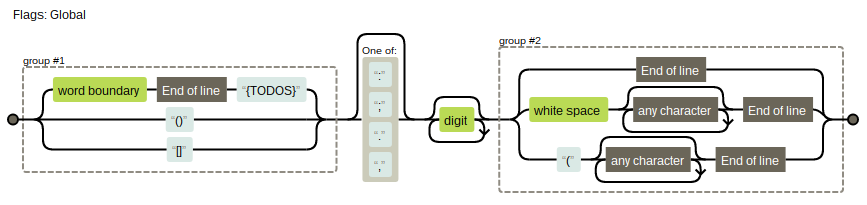
So to recreate adding empty parentheses or an empty set of squared brackets to the list of labels to look for, one only need do change the regex pattern slightly.
/(${TODOS}|\(\)|\[\])[:;.,]?\d*($|\s.*$|\(.*$)/g
You can see the visualisation of the slightly amended regex pattern yourself to check this.
Other behaviour
However, a more radical change is required to get the todo-show table to recognise what is text in a different way.
It’s worth mentioning at this point that, if there is no task text to be found after a label, todo-show will look for the text before it instead.
One can see evidence of this in the table by experimenting and by looking at todo-model.coffee for the todo-show package repo.
# Use text before todo if no content after
if not matchText and match.all and pos = match.position?[0]?[1]
matchText = match.all.substr(0, pos)
matchText = @stripCommentStart(matchText)
This happens a lot for me, as essentially the parentheses I’m looking for always follow the description of the link or image I need to fill them.
Simple solutions
I started to come up with simple regular expressions like, for example, a regex for Markdown image references without image addresses in them.
(!)\[([^\]])\(\))
But I didn’t want to forfeit the normal functionality of todo-show in the process. So I set about trying to integrate my new simple patterns into the existing default pattern that todo-show uses.
This was harder than it might seem.
Integrated regex patterns
I had thought at first that I could simply put the two patterns alongside each other in a non-capturing group.
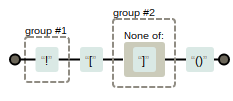
/(?:(${TODOS})[:;.,]?\d*($|\s.*$|\(.*$)|(!)\[([^\]])\(\))/g
Unfortunately, as the visualisation of a disjunctive approach shows the new capture groups would not then be recognised by the code as they are logged as numbers 3 and 4 instead of alternative 1s and 2s.
I found that deeper integration was needed if I wasn’t going to go into the code itself and repurpose the package.
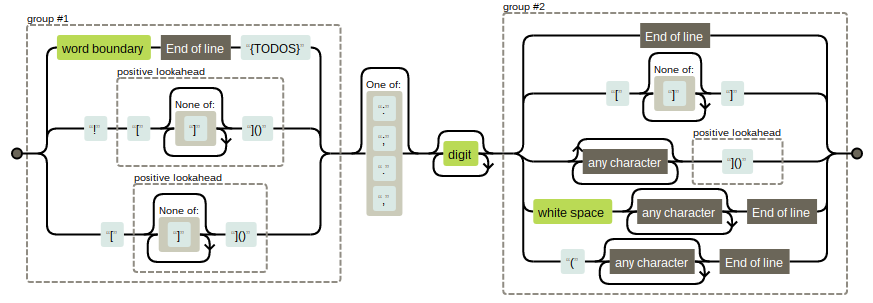
What I came up with involved lookaheads. It is by no means a perfect solution but it does work.
(${TODOS}|\!(?=\[[^\]]*\]\(\))|\[(?=[^\]]*\]\(\)))[:;.,]?\d*($|\[[^\]]*\]|.*?(?=\]\(\))|\s.*$|\(.*$)
You can play around with the visualisation of the integrated solution yourself at RegExper or even try the tests I ran for the integrated regex or simply see it here.
What next?
I didn’t even get on to using tags or trying to escape blockquote or code excerpts. So the solution presented here is not what I originally set out to achieve. But this post attempts to show my thinking around solving the problem.
In all of this, I’ve avoided changing any of the code in the package itself, although I started to look at it to understand what is happening.
However, what this leads me to believe is that there might be a gap in the Atom package market for this kind of cleaning up process. That’s something I may look to produce in the near future.