Using GatherContent for web and print
In the Content Team we often need to use the same facts and information across several different formats or channels. There’s print material to consider, there are webpages to update, and there are even listings on external sites. In this post I explore how we’ve been using a tool called GatherContent has helped us to do this.
Setting the scene
Imagine you’re in a team tasked with writing content about educational courses that’s factually accurate but also makes people want to enrol on those courses. That’s us in the Content Team.
But now imagine all sorts of information and content coming in from different directions. It’s also got to appear across various channels. Lots of different input, lots of potential output.
Some of the input you’re expected to do something with immediately, some of it you’re expected to collate and put online or in print when you have the full picture. It’s hard to know when you’ve got the full picture.
The old model
Now imagine that not only is some of the information or content incomplete, but some of it isn’t that strong. So you hold back or you make changes or try and talk to the person who’s provided it to see if it can be improved. Some people don’t want that conversation though. You’re told you should put up what you’ve been given.
This is the old model for the content on the web and in print where I work. It’s still in some cases the current model but I call it the “old model” in the optimistic belief that it is changing.
The old model wasn’t really a model at all – it was what happens if you don’t have any processes or defined roles in place.
Information or content would fly around by email in different Word documents with odd versioning conventions, sometimes with tracked changes, sometimes with comments in the document, sometimes with comments and complaints in the body of the email messages themselves. It got very hard to unpick what needed to happen to each bit of content, particularly after several drafts or iterations. Difficult for one conversation, virtually impossible for several.
We’re still forced to work like this sometimes now. But we are starting to effect change in the most difficult areas.
Information vs. content
In the section above I hedge my bets by mentioning people sending us “information or content” (emphasis now added).
One key change made when the Content Team came together last year was to stress a distinction between “information” or “facts” on the one hand and “content” or “text” on the other. I like to think that I’ve played an important part in that.
This change of mindset means we can explain and reinforce what it is we do as a team and what it is we expect from others. Others provide information and facts, we turn it into content or text appropriate for the channel it needs to go out on, be it print, the website, or in some currently rare cases, social media.
This doesn’t solve all our problems of course. Simply determining which information is authoritative, getting a single version of the truth has been challenging enough. And that’s not a problem we in the Content Team can sort out by ourselves but we started to develop and design tools to cope with it.
In asserting a distinction between information and content, we have at least been able to funnel the information on our side, get it into one place and organise it for the channels or formats for which we need content.
Channel-neutral content?
In the rest of this post, I’ll be referring to a specific set of projects.
Late last year we were tasked with helping to put together the undergraduate prospectus, the booklet that gets sent out to schools and fairs, is used by people who might think about studying here, and advertises every undergraduate-level course we have available for a specific year. And more recently we are helping with the postgraduate prospectus.
This booklet had always existed but before the Content Team it was worked on by the Student Recruitment Office who also went (and still go) to the fairs and worked (still work) with the designers and printers and drive the deadlines.
Since the arrival of the Content Team and a big project to update the website, it made sense for us to join the other team in putting the prospectus together. If nothing else, we could proof-read what came through and try and ensure consistency between what was being advertised on the web and what was appearing in print.
The aim has been towards moving towards gathering “channel-neutral” information internally so that we can then create content specific to the channel it needs to appear on.
Deciding on GatherContent
We in the Content Team had used GatherContent before for that aforementioned big web project.
However, we were still learning how to use it at that time and, as we were working with some external agencies and we only started using GatherContent halfway through the project, we didn’t use it as fully as we could. That previous project did help me see its potential though.
GatherContent has been an invaluable tool in helping us to funnel information and content (I use both words deliberately now) for use in the prospectus and on the web. It’s easy to set up repositories or “projects” for gathering items and create an editorial workflow around those items. (There is a cost for usage though.)
Tabbed templates
To help reinforce this distinction between information and content, first in our own team and later with others, we created templates. Each template in GatherContent allows you to specify not only fields for filling with content (or in our case information too) but also tabs for organising those fields.
We decided on three tabs for grouping the fields and for helping with this distinction.
“Data” tab
The data tab is designed to contain the essential facts and raw information about a course.
We designed a number of simple fields to capture the title of the course, the qualification on offer, the entry requirements, the fees one has to pay to take it, and internal and external codes associated with it.
We also created open text fields to drop in notes and facts about a course from the person who teaches it. This enables us to capture quickly what they’ve told or sent us but keep it distinct from any structure we might need to give that information.
“Web” and “Print” tabs
We then had separate tabs for where we would write the actual content.
We also include here fields for channel-specific information, for example page numbers to refer to for further information (in the print prospectus) or link text and URLs and tracking parameters (for the webpages).
“Modules” tab
Each course offering is ordinarily comprised of a number of compulsory and optional modules.
We created a separate tab to list these, even though they’re technically a kind of data. But I think the future may like in creating each module as a separate sub-item of each course.
We’re a way off from that though, simply because getting reliable information on modules has been problematic. So this is a provisional tab for now.
Working across teams
Setting up the templates is a start and can take a bit of thought. But then we need to agree how and when the various parts of each should be completed and checked. This is where GatherContent’s workflow feature has helped us.
Agreeing the workflow upfront
I drew up the stages we would need to go through for each course as a table. This then enabled us to discuss the stages and who should take responsibility for each across our teams.
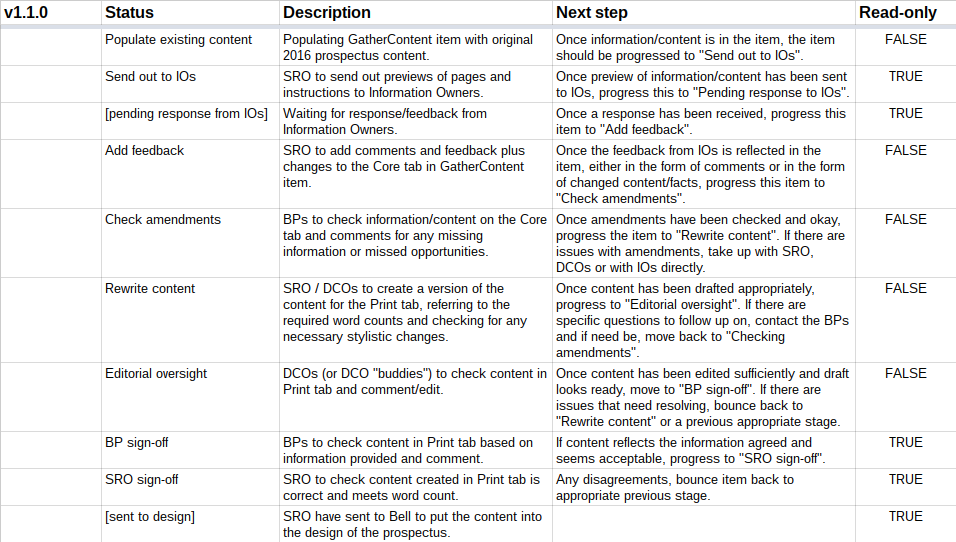
Colour choices
Once we agreed on this, I was able to set it up in GatherContent. GatherContent allows you to assign a colour to each stage which then appears besides content items in a list.
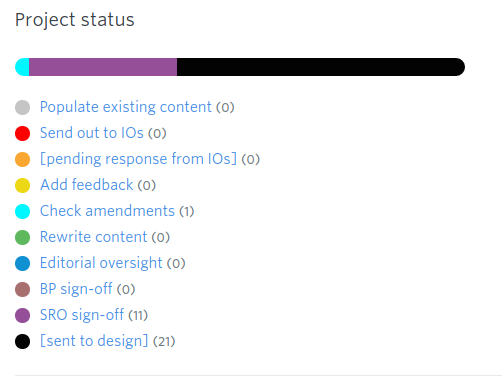
This makes it very easy to see at a glance which stage an item is at.
Linearity vs. circularity
We knew that some stages in reality would be repeated, even though this looks like a simple linear workflow.
For example, whereas we might have acknowledged that an item needs to be checked and signed off by the “information owner”, in reality there might have to be several such checks. Content tends to be reviewed at least twice, once on the initial write-up and again following the incorporation of any comments or feedback.
We toyed with creating a long list of stages to account for this but in the end we agreed it would be better to re-use the stages where could. There might be many more than two checks for each item and not knowing meant it seemed safer to ensure that everything passed through a stage once and bounce it back as needed, rather than duplicate the stages for the second round.
So, although the workflow looks linear, we actually use it cyclically where needed. We bounce items back to a previous stage where rewriting is needed, several times if we have to, until it’s ready to progress.
This can get a bit confusing, as it’s not easy to tell how many times an item has been through a particular stage. We have been using comments and notes on the item to try and track this, but I’m still not convinced we’ve cracked it. We will need to rethink this before our next project.
Adjusting the workflow
Having said that, we’re open to adjusting the workflow by adding, editing or removing stages at any point, even in the middle of the project – whatever it takes to make the process more efficient, as long as it can apply to all the items in the project.
We might add a stage to acknowledge a task that could be better done in a batch – in those cases it makes sense to acknowledge this in the workflow.
Some tasks however can be lumped together and, if that’s the case, we might edit one stage and remove another now superfluous one.
In this way, we keep trying to avoid bottlenecks in the process. That said, we’re careful not to remove stages that we feel are essential just to speed things up.
Success and future aims
For the print material, there comes a point where we need to send the content off to the designers or start loading it into the webpage so that we can see how it looks in the medium it’s meant for.
For the prospectus this means the final stage in GatherContent is “[sent to design]”. After this point, we look forward to receiving the design files where we continue our commenting and discussion there.
Commenting on the design files is easier in one sense but does, at that point, create duplication. If facts in the design need correcting, we also then need to correct them in the GatherContent repository. Otherwise the changes won’t be applied to other content due to appear elsewhere.
It may be fairly clear now that we’re moving towards a model of using GatherContent for storing all our facts and information and the variants of content we need to produce for each channel. But there’s still some progress to be made in putting this model in place.
Next
All of the above describes a fairly basic use of GatherContent.
I appreciate the storage of facts and information might not seem all that novel. In my next post on this, I want to talk about some of the more experimental things we’ve done using GatherContent. Here are a couple to look forward to:
- HitherContent. Using GatherContent’s API I’ve created a script that allows to display and share content to our “clients” in a different way.
- Modelling information architecture. We’ve started moving towards using GatherContent’s hierarchy of items as a way of actually structuring the content, determining what constitutes a page, which level chunks of content should sit at and so on.
I look forward to writing about these areas soon.