Automatic Git patch generation at word diff level
Last post, I bemoaned the lack of Git’s ability to let you select word-level diffs for staging and committing. Almost a month on, I’ve tried to come up with a possible technical solution to this.
Quick re-cap: the problem
Imagine you have made some changes to a file and you are versioning it with Git.
But also imagine there are some lines you want to stage and commit, and some you don’t. Usually, that’s easily done with git add -p.
But now imagine there are changes within those lines you want to stage and commit while ignoring other changes within the same line. Let’s call these word-level changes instead of line-level changes.
Git won’t let you do word-level changes, not without some serious working around (which I detailed last post).
You might think this seems like an unlikely problem for coders to encounter. Significant change tends to happen at the line level. That’s why Git is based at the line level, after all.
But, for anyone using Git for managing and versioning prose, word-level changes are much more meaningful and Git’s lack of ability for dealing with them can be very limiting.
My last post gives a full outline of the problem with examples.
A possible solution
I started down the road of creating a shell script to start dealing with this issue. It’s limited for now, since it can’t deal with multiple lines – but it’s a proof of concept and it works for the single line example I showed in my last post.
How you’d use it
You call the script with a filename as an argument – the name of the file you want to selectively stage, as you would with git add -p.
The script then gives you each word-level change and asks if you want to select that change for staging or ignore it. You choose by entering “y”, to select it, or “n”, to ignore it, or “q” to quit the process altogether. (Again, a bit like git add -p, minus a few options.)
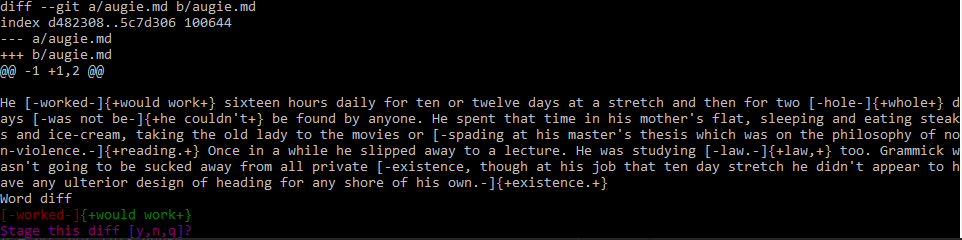
At the end it takes all the changes you have selected and creates and applies a patch of just those changes for you. You then just need to commit what’s staged as you usually would.
Before you commit:
- You can run
git diff --word-diff --cachedto see the changes you selected are staged (and if you’re happy you can commit them). - You can also run
git diff --word-diffto see the changes you ignored for staging this time around. - You can undo the application of the patch, as you normally would, with
git reset.
How it works, for now
-
The script starts by calling
git diff --word-diff -U0for just the filename you provide. If you don’t provide a filename, the script will throw an error. -
The script then takes only the lines that have changes and loops through each one noting where it is in the file.
-
While looking at each line, it then loops through each of the changes found within the line.
-
It displays each change to you separately to make the choice of selecting or moving on.
For each change it is gradually building a patch by taking the line and replacing the word diff with either the content of the new change, or a restatement of what’s already in the file.
- Once it’s done that with all the lines, they all get put together with the head of the original patch, which details the file to change and that gets applied with ‘git apply’.
Challenges I faced
For those interested, rather than comment on the script line by line, here are the initial challenges I encountered in writing it.
Looping through found changes
I’m wouldn’t say I’m an expert with Bash so there were a few stumbling blocks that those with more experience would probably not have encountered.
-
Loop version 1
The first was working out how to go through each change in the line to offer the user of the script a choice about what to do with it.
I knew enough to know that
grep -Pofollowed by the right Perl-flavoured regular expression would return a bunch of results. I had no issues creating the regex. But I didn’t know how to work with those results.I kept looking up how to assign the results to an array of some kind, but that seemed tricky.
Eventually I realised I could build the loop around this
grepcommand without needing to assign the whole set of results to anything.I started by calling echoing the text of the line, piping that to my
grepcommand and then piping that to awhile readloop.echo "$diffline" | grep -Po '(?:\[\-(.*?)\-\])?(?:\{\+(.*?)\+\})' | while read diff; do # rest of code within loop doneThat was fine to begin with but I found outside the loop when I wanted to compile all the changes, nothing had actually changed.
-
Loop version 2
Later, I learnt that I was trying to assign changes to a global string variable (so that each change could be easily recalled later), but that by the time I exited the loop all those changes would be forgotten.
I learnt that piping results creates a sub-shell which seems to have its own scope for variable assignment. So I found a different way to write the loop, using something called process substition.
while read diff; do # rest of code within loop done < <( grep -Po '(?:\[\-(.*?)\-\])?(?:\{\+(.*?)\+\})' < <( echo "$diffline" ) )
This allowed changes to be retained within global variables outside the loop.
Replacing changes with text
Next, I had issues actually replacing the changes found by git diff --word-diff with the decided-upon text.
It turned out this was because changes in the output for git diff --word-diff contain special characters that are meaningful in the context of Bash’s string parameter substitution process.
Quick summary – Bash’s string parameter substitution process allows you to name a string variable, provide a pattern, and then provide a replacements string. Like this:
${variable/pattern/replacement}
The problem I encountered is that the string I was providing for pattern would by definition contain characters problematic for Bash – specifically [- and -]. Let’s think of those characters as the removal wrapper.
It took me a while and some testing to realise this is what was going wrong. But as soon as I did, I could write some code to fix it.
if [ ! -z "$old" ]; then
ptn="\[\-${old:2:-2}\-\]$new";
else
ptn="$new";
fi
Acknowledging that there wouldn’t always be removal within a recognised change, I allowed for instances of pattern (ptn) where the variable would $old would have a value or not.
Where it had a value, I provided the wrapped it in escaped version of the the removal wrapper. Where it did not, I simply specified that ptn should be $new, that which was added.
Nesting loops
Finally, once I had gotten the looping through changes working and the substitution working, I realised I would need to know how to build the patch together again.
So I created an outer loop that would simply go through each line of the patch provided by git diff --word-diff.
First, I separated the first four lines of the patch and called that filehead, as these simply contain metadata about the changes.
Then the outer loop goes through each line of the rest.
I started with an empty variable called patchcontent, looking to append to that any outcome from the loop.
Each changed line from the file also has metadata preceding it, to say where in the file the changed line sits. These lines begin with @@ before providing line numbers. So I simply concatenated these lines unchanged onto the end of the line, not caring much for what was in them.
For any changed lines, the inner loop would cycle through all the word-level changes it could find.
At the end of both loops, the concatenated changed lines and their metadata would be prepended with the filehead and this would then constitute the patch to be applied.
What next?
Having successfully written a script that can deal with a word diff changes within a single line, I want to expand it to deal with changes across multiple lines and even multiple files.
But that will required some more thinking and probably some refactoring of everything I’ve just described!