Creating HitherContent
I created a package for Node.js that enables simple interactions with GatherContent. I’ve used this successfully to retrieve content that the team has been working on and create preview pages of content which we then share with stakeholders for editing and checking.
Using GatherContent in the team
Back in June, I wrote a post on how we use GatherContent in our team to separate “information” and “content”. We gather facts from stakeholders and we turn this into print-ready or web-ready copy. In short, we adapt the statements and messages we get to the needs of the medium or channel we’re using.
I wrote then that, in order to do this, we have created templates with fields organised into tabbed pages so that we can separate raw information or data from the content we’re writing to appear in the relevant public space.
GatherContent does not have any limit (with our license) on the number of users and roles you can set up to work on a project. We’ve used this successfully to work on content for projects that span across teams.
However, when it comes to opening this out to “information owners” – our clients, if you like – we’ve been reluctant. This is less about exposing all the data and raw information and the contrast with the content we are writing – after all, we welcome that comparison – and more about the overhead of having to explain how to read the templates and train people on how to use or interact with GatherContent.
Previewing content
The templates are designed to help with our internal workflow and make us as efficient as we can be. They are not therefore designed to show how content might flow from field to another.
Nor do they standardise headers or elements that appear on pages which provide context for end-users and would help our clients see what we’re shaped the content to.
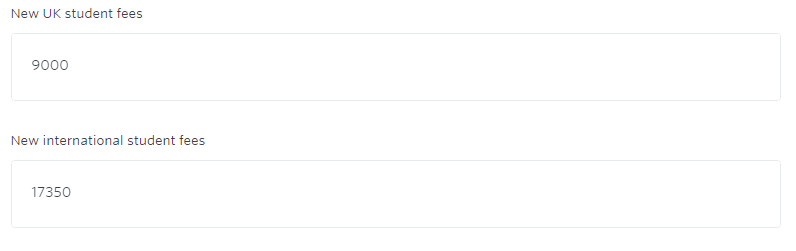
This is particularly awkward when information is spread across tabs. To give one example, we might have information about fees and figures on the data tab.
But then the information about the page number would be located on a print tab.
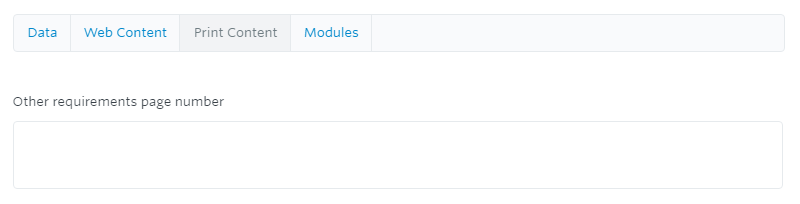
The two bits belong together as content but for our workflow they are processed separately – the first is determined by the latest figures we are given, the second by the limitations described by the designers of the print material. Furthermore, the page number is irrelevant to the webpage information where instead we might include a URL and a call to action.
To avoid having lengthy conversations explaining which bits need to be read and how they will fit together, we recognised a need to share what was taking shape quickly and easily with each other and with the “information owners”. And we didn’t want to resort to copying and pasting into Word documents which is laborious, time-consuming and would return us to our original problem of managing email trails and different versions of documents.
What we needed was a way to extract the information form GatherContent and organise the various blocks of information and content in different ways.
GatherContent’s API
Fortunately, GatherContent has an API that allows us to do this. I started using the API well over a year ago but I never found the time to write about it. Until now, of course.
There’s plenty of great documentation explaining how to go about this at the developers’ section of GatherContent’s support site.
They give clear examples of using cURL and PHP to access content. For example to access information about your own account or profile you can use this cURL command:
curl https://api.gathercontent.com/me \
-u you@yourdomain.com:<YOUR_API_KEY> \
-H "Accept: application/vnd.gathercontent.v0.5+json"
This will return some JSON that one can then parse for the information one wants.
I thought it would be useful to actually write some code to process this in JavaScript, which is JSON’s natural home. So I started playing at first and then gradually building something in Node.js.
My first Node.js package
Creating this was exciting. It was the first proper Node.js package I created and published.
It isn’t particularly revealing that I called the Node package HitherContent as a pun on GatherContent.
I’ve since written about the Dickie Dates Node package I created, which is much simpler and which I outlined in my guide to creating a basic Node package and the follow-up post on dealing with various hygiene factors around Node packages.
Usage
The package I’ve created is still, at present, very simple.
I started out by creating a function for fetching the JSON that GatherContent offers via its API. I called this function getJSONfromAPI.
It took, and takes, any of the possible GET requests listed in GatherContent’s API support documentation.
The only method I created initially was a method called init to help with authentication. So before using the object provided by the package one would feed the object with one’s details so that it could request items from GatherContent at any time.
Extending the package
However, when I started writing code around the use of the package, I realised that I was still writing a lot of duplicate code that might be better in the package itself.
Navigating config
The first example of this involved the config field that GatherContent returns for each item in any given project.
The GatherContent API documentation actually has a page on the config property. Although it’s more geared towards posting information to GatherContent, it describes the structure in detail.
When you request an item from GatherContent, the actual values you’ve entered as content into it are nested within this property. First, config itself is an array of the tabs you have in any given item. Above, I described the tabs we set up for our work on the undergraduate prospectus – “Core”, “Web Content” and “Print Content”. Each of these will be an element within the config array.
Within each tab element there is then a further array called, confusingly, elements. And each of the objects in this array represents each field within the fetched item. So there will be separate objects for the “New UK student fees” and the “New international student fees” for example, and for any other field in each tab.
Flattening objects
And that’s not all. Each of these objects contains a whole bunch of properties for information about that field, aside from the value that the author or editor of the item might have entered.
I wanted to simplify this drastically so I created a method called reduceItemToKVPairs which reduced or flattened each item in GatherContent to what I considered to be essential values.
So content nested several layers deep like the “Call to action web link” on the “Web content” tab could be found as a property at the top-level of the item called “Web-content_Call-to-action-web-link” and the value of that property would simply be the content contained within the field.
Content hierarchy
GatherContent provides a neat way of nesting items themselves to show information hierarchy within a project.
We’ve found that helpful in being able to differentiate the courses that are actually on offer and the subject labelling and descriptions they actually appear under.

However, when you request a project’s worth of items from GatherContent, they come as a flat array within only pointers inside them to indicate which items they might sit under. The pointer is a property called parent_id.
For previewing content for the prospectus and for sharing this content more widely for checking, I wanted an easy way to show items grouped together as they would be in the prospectus. However I realised such a feature would be more helpful more generally.
Fetching branches
I decided to create a method called getProjectBranch, which could be used to fetch an entire project or an individual item within that project. But when selecting an individual item it would come with some additional properties – it would come with an array called items containing all the items that were organised beneath it on GatherContent and it would come with a property called tier to show its position within the tree.
This was a tricky function to write and I resorted to using a Node package called async (although I believe this functionality is now a native part of the ECMAScript 6 standard). I’m sure there’s a better and less resource-costly way to write it, and looking at that is on my to-do list.
In any case, it’s been invaluable being able to easily pull together items in this way.
Summary
I’ve tried here to give an account of work that undertaken in bits and pieces in reaction to needs we had as a team over the past work. Hopefully, it’s a coherent account for anyone interested in the whats and whys of HitherContent – although I’ve been a bit shy about the hows, because I think the code itself could do with refactoring.
Next
I would like to write a post about how we’ve been using this with Heroku to serve content up to people.
More recently, we’ve taken what I believe is a more radical approach to managing content on GatherContent, which I also want to describe in a future post.
And I have other ideas about how to improve the package which I’m currently casually recording on the issues log in the HitherContent repo.
More to follow soon.