Content delivery from GatherContent – with HitherContent, Heroku, and Handlebars
We’ve been using GatherContent in the Content Team in a couple of different ways. This post talks about one of those ways. In doing that, it covers how we’ve used my HitherContent package along with the templating engine Handlebars and the cloud application platform Heroku to serve the content we’ve produced.
Previously on…
Back in June, I published a post on how our team use GatherContent. I described how we used different tabs in GatherContent templates to differentiate between information (or raw facts and stats) and the content we wanted to eventually work up.
Then, at the end of October, I finally got around to writing about the package I’d developed to help us with this. In that post, I gave an account of the creation of HitherContent but I didn’t really talk about how we have used HitherContent in practice.
I also described how HitherContent not only takes the data from GatherContent but also “flattens” it out, if desired. So an intricate and multiply nested config object in one item can be reduced to a simple and flat list of properties containing the value of the content for each field in any GatherContent item. This provides just the information we need to use and nothing more.
However, I did not cover how these new flattened fields are then used. That’s what I seek to explain in this post.
Riding Handlebars
To explain how we used the data extracted from GatherContent, I need to briefly explain Handlebars.
Handlebars is a nice, almost logic-less templating engine. And a templating engine is a tool that enables you to write templates, leaving certain spaces blank to be populated by different values based on whatever information you give it. I’ve written about this before in one of my more popular posts, comparing Handlebars to a very similar templating engine, Mustache.
As a templating engine, Handlebars has allowed me to create mock-up webpages and insert variables where I would like the content to vary based on whatever I pull out of GatherContent. To do this with Handlebars, you simply need to give the template a “context” – that is, an object containing all the variables in the template and their values – and Handlebars will do the rest.
All ironed out
As explained in my previous post, the context is fetched from GatherContent by HitherContent.
A simple request for the JSON from GatherContent, untreated, would return something like this, even just for a single field element within config:
"config": [
{
"label": "Content",
"hidden": false,
"elements": [
{
"type": "text",
"name": "el1429200091126",
"required": false,
"label": "Page header",
"value": "Some text",
"microcopy": "",
"limit_type": "words",
"limit": "0",
"plain_text": false
}
]
}
]
This is useful information about the field but we don’t need all of it for our Handlebars template. We just need the content so that we can use it with Handlebars as a template’s context.
Fortunately, using HitherContent’s getProjectBranch method and reduceItemToKVPairs all the items can be flattened and nested appropriately so that the element shown above would simply be represented like this:
"Content_Page-header": "Some text"
Notice that, from all the properties provided by GatherContent originally, the label for the tab and the label for the element are combined into a single property name and that only the value is attached. The other information is stripped out; the element “flattened”. This is all the context we need to start building pages.
Croggying context
With this minimal context, we can then start creating a template based on these composite variable names. For example:
<html>
<head>
<title>{{Content_Page-header}}</title>
</head>
<body>
<h1>{{Content_Page-header}}</h1>
</body>
</html>
In the above example, I’ve simply used the variable flattened above to act as both title and primary header for a page. But we can take any field from a GatherContent item we’re requesting and use the variable name we know HitherContent will generate to represent a value in the template.
Fresh and frozen
Obviously a script is needed to put the template and the context together. For the purposes of our work on the undergraduate prospectus, I wrote two such scripts:
- One script for serving the pages instantly at any time, so the team could see the content in one place. We can think of this as “fresh” content – if you refresh the page served, it will show whatever is on GatherContent at that point.
- One producing a series of files ready to send to our designers. We can think this as a “frozen” version, package and ready to be opened at any time. But it only represents the content at the point in time that it was produced.
Preview generation
The first script was designed to provide an instant look at what was on GatherContent at any moment.
I wrote a Node file in JavaScript using the package Express to do this. On requesting the root, it would fetch and display a list of all the subject pages in our project.

On requesting a given ID number, it would request that item – normally a single subject item – with any other items nested beneath it included, using the getProjectBranch function.
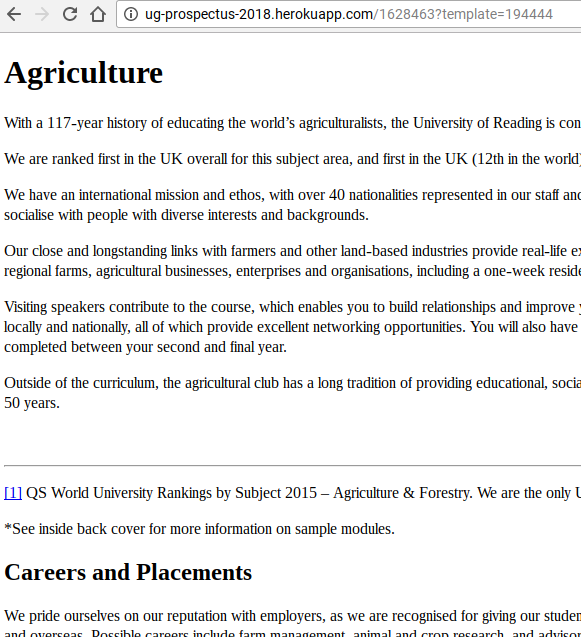
This means that each subject page template also needs to show all the items beneath it.
Nested partials
Normally anything nested within a subject page item is a course page item, as courses are grouped by subject in our GatherContent project. There are a few exceptions but, for the simplicity’s sake, I’m not going to discuss them.
The course items themselves might have courses nested beneath them. We use courses nested underneath higher-level courses to represent variants of the higher-level course. For example, some courses are also offered with a placement option which forms part of the degree title. These variants need representing within the prospectus too but we don’t need as much detail for them.
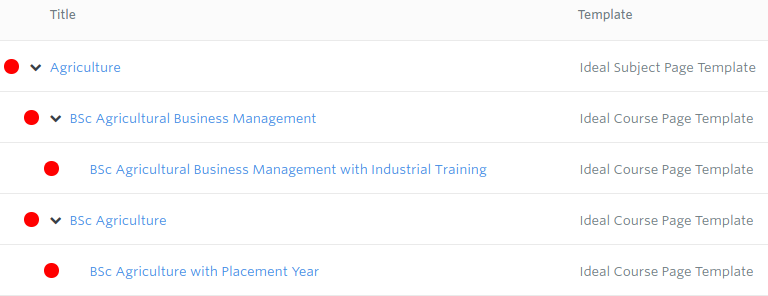
On the templating side, the course items beneath a subject are handled by a Handlebars #each loop. This loops through all the items nested immediately below the subject item returned by getProjectBranch:
<div class="courses">
{{#each items}}
<div class="{{_template_id}}_listing">
{{> (whichPartial _template_id) this}}
</div>
{{/each}}
</script>
</div>
Each item in the loop is then rendered by a partial template. A “partial” is simply another template file containing Handlebars variables for a chunk of a page. The partial for a course item begins like this:
<div class="course-title"><b>{{Data_Qualification}} {{Data_Bare-Title}} {{Data_UCAS-code}}</b></div>
<div class="course-data">
<b>Full-time:</b> {{Data_Full-time}}{{#if Data_Part-time}} | <b>Part-time:</b> {{Data_Part-time}}{{/if}}{{#if Data-Flexible}} | <b>Flexible:</b> {{Data-Flexible}}{{/if}}
<div class="placement-courses">
{{#each items}}
{{> placement this}}
{{/each}}
</div>
There’s more to this, but hopefully it’s obvious that the course title is represented first, followed by the course duration for full-time, part-time, and flexible variants.
Crucially though, there is then another #each loop to capture any items nested below the course item in GatherContent.
These placement-variant courses are rendered with a partial called placement which simply lists the variant title and duration in each case, like this:
<div class="course-placement-title"><b>{{Data_Qualification}} {{Data_Bare-Title}} {{Data_Inclusions}} {{Data_UCAS-code}}</b></div>
<b>Full-time:</b> {{Data_Full-time}}{{#if Data_Part-time}} | <b>Part-time:</b> {{Data_Part-time}}{{/if}}{{#if Data-Flexible}} | <b>Flexible:</b> {{Data-Flexible}}{{/if}}<br>
This renders variant course titles directly under the primary course title but nothing more.

Why use variant items?
So “Agricultural Business Management with placement year” is listed directly beneath its parent course in GatherContent “Agricultural Business Management”. Below those two titles, for the purposes of the print prospectus, the content is the same.
This might raise question as to why we would bother having a separate item in GatherContent for the variant courses – why not just include a field on the primary course item that gives an opportunity to list any such variant options.
There are two reasons:
- We still want to standardise information and having an item for each variant makes this easier. Although because we don’t require as much information for print, the templates could arguably be simpler.
- We still need content about these courses to put on the website, where the constraints of the print publication don’t count. If we don’t have separate items for each variant, we risk having to come up with another divergent method to represent this content.
Using Heroku
For the purposes of delivering the fresh content, I set up an account on the cloud application platform Heroku.
The way I use Heroku is really just as a server or router for displaying different items in GatherContent. To do that, I wrote a script that listened out for different pathnames and displaying the content from GatherContent accordingly.
The whole script is dedicated to one project in GatherContent. So I took the GatherContent project code and put this in a private .env file along with my account credentials, to make sure I didn’t accidentally make them public. When I run the server locally using heroku local it simply serves a list of subject items from GatherContent.
The code for this bit is quite simple. I wrote it so long ago, I don’t even use the getProjectBranch method I developed in HitherContent; I use my very basic getJSONfromAPI method instead:
var path = "/items?project_id=" + process.env.project
app.get('/', function(request, response) {
hithercontent.getJSONfromAPI(path, function (d) {
var template = "root",
source = fs.readFileSync("./views/pages/" + template + ".html", "utf8"),
layout = handlebars.compile(source),
result = d.data
.filter((v) => (v.parent_id === 0))
.filter((v) => (v.name !== "Miscellaneous" && v.name !== "Defunct"))
.sort((a, b) => (a.name > b.name ? 1 : -1))
response.send(layout(result));
});
});
This requests project information from GatherContent, filters out any items with a parent (so only gives us top-level subject items), filters out the items called “Miscellaneous” and “Defunct” and sorts them by name.
It then applies the Handlebars template to them, which in this case is very simple:
<html>
<head>
<title>List of subjects</title>
</head>
<body>
<h1>Undergraduate Prospectus 2018 Content Preview</h1>
<p>The list below provides previews to the most up-to-date versions of
content on GatherContent for the Undergraduate Prospectus 2018.</p>
<ul>
{{#each this}}
<li>
<a href="/{{id}}?template={{template_id}}">{{name}}</a>
</li>
{{/each}}
</ul>
</body>
</html>
The end result for this was shown earlier.
You might see from the code that generates this page that each subject link is simply the ID for the given item in GatherContent. It’s represented by the code <a href="/{{id}}?template={{template_id}}">{{name}}</a> within the each loop.
So the script I wrote is designed to received these IDs and when it does it calls GatherContent for the detail about that specific item.
It then generates a page accordingly. The code for this is a bit more complicated so I won’t detail it all here. It probably needs rewriting anyway. But hopefully, you can see that the principle is the same.
In this way, the team can work on an item in GatherContent and then go to a web address to see their content displayed as a basic page instantly, giving them a feel for flow of the copy and an idea of what might need amending.
Packaging up for delivery
One last thing to mention in this post, which is the “frozen” part. I’ve just described the “fresh” bit which allows the Content Team, and any others we share the link with, to see the copy updated automatically from GatherContent.
For the designers we are working with however (an external agency) they need a single iteration or draft of the copy to work that will remain stable while they get them into the designs they are working on for print. The items on GatherContent are constantly seeing minor changes so providing them our live server version is not practical.
So I wrote a simple build script which would, like the fresh version script, pull all the content from GatherContent and template it with Handlebars but would not then serve it to an address but would write resulting code to static webpage.
I could then easily zip all these pages up and send them over to the designers at key points.
Success and future improvements
There’s much I could to improve the code of both the server and the build script so that I could make it more generally available but so far this has successfully enabled us to see instantly the items we are working on as they should be grouped and send the content off in a package to our design agency.
Much could be done to improve the styling of the previews but that hasn’t been necessary so far.
I mentioned right at the beginning of this post that this is one of the models we have been using for shaping content as we work on it in GatherContent. The other model is much more about rapid prototyping that content checking and delivery, so I hope to talk about that in a separate post very soon.