Accessing files from the GatherContent API
We’ve recently entered a new phase of using GatherContent, here in the Content Team. Now we’re using GatherContent to rapid prototype webpages. In order to do this effectively, I’ve had to update the HitherContent package I’ve been working on to not just fetch textual values but also files, like images, from GatherContent projects. This post describes what I found out in the process.
What HitherContent is missing
When I started developing my Node package, HitherContent, my main focus was on extracting the content that members of my team were writing so that we could work with it in other ways outside of GatherContent while keeping the workflow and collaboration that GatherContent offers.
The reason HitherContent hasn’t dealt with files before is because GatherContent treats files in a peculiar way. I had to learn more about that before I could make HitherContent work for our new rapid prototyping approach.
How GatherContent handles attachments
If you request an item’s details from GatherContent it will return the details of almost all field types – text, guidelines, checkboxes and radio buttons.
But there’s one field type that GatherContent will not return a value for, despite its appearing alongside all the others as a normal field: attachments.
When requesting information from the API, one must request information about any attachments for an item separately.
Rather than simply getting the data about attachments alongside everything else with a GET request to /items/<ITEM_ID>/, one has to make a separate GET request to /items/<ITEM_ID>/files.
Attachments data
If you request files or attachment data from an item in GatherContent, you get all the attachment details.
This is the example that GatherContent’s help documentation gives:
{
"data": [
{
"id": 1,
"user_id": 1,
"item_id": 1,
"field": "abc123",
"type": "1",
"url": "http://link.to/filename.png",
"filename": "original.png",
"size": 123456,
"created_at": "2015-12-10 18:49:17",
"updated_at": "2015-12-10 18:49:17"
}
]
}
The most important properties returned about the attachment in terms of simply getting the relevant files are:
field: This relates to thenameproperty for any element returned in a GatherContent item so it’s important for matching each item to the field or element it belongs to in GatherContent.url: This is the address used to get the file itself.
Getting the files
Once you have the URL, you can simply request it, no authentication details required.
Ricardo Magalhães from GatherContent has produced a script to get files for a GatherContent item with Node JS.
He and I talked about doing this with GatherContent as we were developing approaches at the same time.
Accessing files with HitherContent
I started to think about what I wanted HitherContent to do with respect to this. I realised a method for requesting just file information was important but I also realised that this would need integrating somehow into other methods.
So before I started coding, I tried to articulate these requirements more clearly and write some tests accordingly.
Requirements
Ultimately, I thought it would be helpful to have files elements listed alongside elements in the data.
For example, we have a template in our rapid prototyping model called “Banner and message”. It contains a few fields, among them a file/attachment type field.
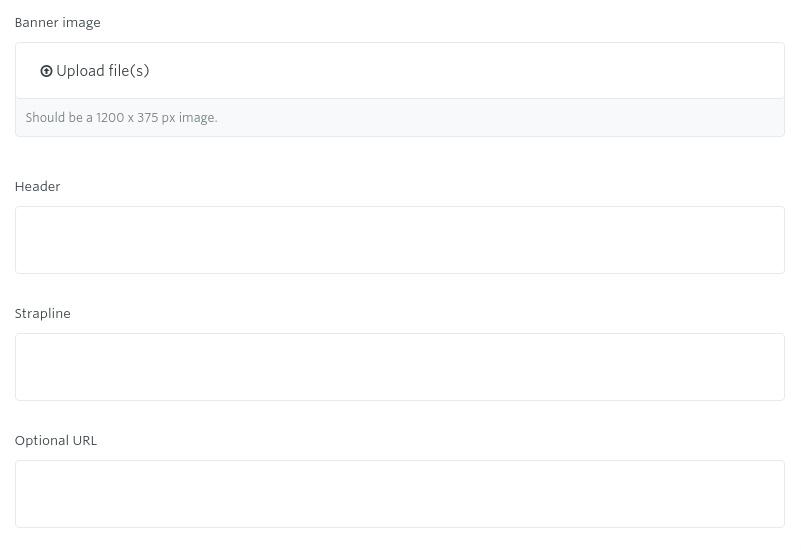
GatherContent does return details about the attachment, as mentioned above and as we see by looking at the elements object in the JSON return for this item:
"elements": [
{"type":"files","name":"el1476890603948","required":false,"label":"Banner image","microcopy":"Should be a 1200 x 375 px image."},
{"type":"text","name":"el1476890716582","required":false,"label":"Header","value":"Outstanding career prospects","microcopy":"Should be 2-3 words maximum.","limit_type":"words","limit":0,"plain_text":true},
{"type":"text","name":"el1476890734269","required":false,"label":"Strapline","value":"96% of our graduates are in work or further study six months after graduation","microcopy":"Should be 8-10 words maximum.","limit_type":"words","limit":0,"plain_text":true},
{"type":"text","name":"el1476890752932","required":false,"label":"Optional URL","value":"","microcopy":"Optional link for banner.","limit_type":"words","limit":0,"plain_text":true}]}
]
However, traditionally, HitherContent could only return a flattened version of all fields except the attachment field.
"Content_Header": "Outstanding career prospects",
"Content_Strapline": "96% of our graduates are in work or further study six months after graduation",
"Content_Optional-URL": ""
This is because the code in HitherContent simply did not recognise the “files” type:
if (v.type === "text") {
item[k] = v.value;
} else if (v.type === "choice_radio") {
item[k] = v.options.filter(v => v.selected).reduce((p, c) => p + c.label, "");
} else if (v.type === "choice_checkbox") {
item[k] = v.options.filter(v => v.selected).map(v => v.label);
} else if (v.type === "section") {
item[k] = v.subtitle;
}
The reason this was not accommodated is that there was simply no way to deal with getting the actual value for such a field without making a further API request, something that seemed overly complicated for the original requirements I had.
However, what I wanted to see was “files” type elements (corresponding to attachment fields), treated in the same way, so that the HitherContent “reduced” output would look something like this.
"Content_Banner-and-message": [ "http://link.to/filename.png" ],
"Content_Header": "Outstanding career prospects",
"Content_Strapline": "96% of our graduates are in work or further study six months after graduation",
"Content_Optional-URL": ""
The use of the array in the flattened "Content_Banner-and-message" property above allows for the possibility of multiple files or attachments for an element as GatherContent also allows this to happen.
Behaviour-driven files access
To achieve this aim, I decided I was going to write a new function for my HitherContent package called getFilesForItem.
Following the practice of behaviour-driven development, I decided to write a suite of unit tests that would describe the behaviour I wanted for the method, give me an instant measure of how much progress I’d made, and help prevent breakages.
The suite can be seen in the file api-files.js on the HitherContent GitHub repo. It contains tests on what happens when an item with one file is requested, what happens when an item with two files is requested, and what happens when an item with one file but several other field types is requested.
Specifically, it contains tests like these, where test data are checked after they have been through getFilesForItem to see if they now have url and filename arrays.
it("should return an object where the single `url` element is `http://link.to/filename1.png`", function(done) {
hithercontent.getFilesForItem(project_content["1"], function(item) {
expect(item.data.config[0].elements[0].url[0]).to.eql("http://link.to/filename1.png")
done()
})
})
it("should return an object where the single `filename` property is `file1.png`", function(done) {
hithercontent.getFilesForItem(project_content["1"], function(item) {
expect(item.data.config[0].elements[0].filename[0]).to.eql("file1.png")
done()
})
})
The tests are written in the Chai syntax and executed using Mocha, as described in my post on behaviour-driven development.
As you can perhaps see, the tests expect url and filename arrays, containing the URLs and filenames respectively, for the files associated with the relevant fields.
The getFilesForItem method
The getFilesForItem method I wrote to produce this behaviour is pretty simple. It requires just two arguments: the item object itself from GatherContent and a callback argument to execute on it.
The reason it requires the item itself rather than just an ID for the item is because the method will actually add the information it finds about the files to the item itself.
So, whereas previously just getting the item data from GatherContent told you there was an element that accepted attachments in the item, this method takes that same item, requests the file information for it, and adds that information to the relevant field.
Here’s part of a normal GatherContent item (which can be retrieved by getJSONfromAPI method in HitherContent):
"item": {
"data": [
"id": 123456,
"project_id": 123456,
"parent_id": 0,
"template_id": null,
"position": "11",
"name": "Home",
"config": [
{
"label": "Content",
"hidden": false,
"elements": {
"type": "files",
"name": "el1476890603948",
"required":false,
"label": "Banner image",
"microcopy":"Should be a 1200 x 375 px image."
}
// and so on...
Here’s the same part of the GatherContent after it’s been passed to the getFilesForItem method:
"item": {
"data": [
"id": 123456,
"project_id": 123456,
"parent_id": 0,
"template_id": null,
"position": "11",
"name": "Home",
"config": [
{
"label": "Content",
"hidden": false,
"elements": {
"type": "files",
"name": "el1476890603948",
"required": false,
"label": "Banner image",
"microcopy":"Should be a 1200 x 375 px image.",
"url": [
"http://link.to/filename1.png"
],
"filename": [
"file1.png"
]
}
// and so on...
You should see in the second excerpt of code that additional array fields for url and filename have been added. The actual URL and filename given within these new arrays are, of course, just examples.
How getFilesForItem method works
First, the method starts with an empty array and loops through each element in the item (here called item) adding any of the files type it finds to relevantElements:
var relevantElements = []
if (Array.isArray(item.data.config)) {
item.data.config.forEach(c => {
if (Array.isArray(c.elements)) {
relevantElements = relevantElements.concat(c.elements.filter(v => v.type === "files"))
}
})
}
If, after this, the array relevantElements has any file-type elements from the item in it (and it should now contain all that are there), an API request is made for the files contained within that item. This data is then looped through to match each file with the element to which it belongs and add the relevant information – url and filename – to arrays for that element.
if (relevantElements.length > 0) {
getJSONfromAPI(`/items/${item.data.id}/files`, filesData => {
filesData.data.forEach(f => {
relevantElements.forEach(e => {
if (f.field === e.name) {
e.url = Array.isArray(e.url) ? e.url.concat(f.url) : [f.url]
e.filename = Array.isArray(e.filename) ? e.filename.concat(f.filename) : [f.filename]
}
})
})
callback(item)
})
} else {
callback(item)
}
Once this is all done, the callback is invoked with the augmented item as its argument. And, if there are no file-type elements to bother with, the callback is invoked with the item anyway, albeit non-augmented.
Integrating with branch management
For our rapid prototyping purposes (which I’ll explain fully in a post very soon), we have been using HitherContent’s getProjectBranch method which can fetch not just a single item but all the child items that sit below it on GatherContent, creating a nested structure. I describe this method in a section of my post on creating HitherContent
I wanted to integrate the new getFilesForItem method into getProjectBranch but without jeopardising the existing functionality. And, since the existing method relies on optional arguments and relatively complicated asynchronous recursion, I decided it would be simply to write a new method.
So I did.
The new method is called getProjectBranchWithFileInfo. The reason I decided not to make getting the file information a default part of the existing method was because getting file information requires another API call. And when several nested items are involved, this potentially doubles the amount of time the method might take. That’s a lot of time if there are a lot of child items within a branch.
So where in getProjectBranch I kickstart the recursive calls with this line:
getJSONfromAPI("/items/" + root_id, item => findChildItems(storeItem(item)))
In getProjectBranchWithFileInfo, I kickstart the same set of recursive calls with this line:
getJSONfromAPI("/items/" + root_id, item => { getFilesForItem(item, (item) => { findChildItems(storeItem(item)) }) })
This works quite well. Unfortunately, it means a lot of duplicate code, violating the programmer’s principle of DRY (“don’t repeat yourself”). I also did not write tests for this function in the same way that I did for getFilesForItem. The simple and almost indefensible reason is that I was in a hurry.
Next time…
There are a couple of steps I see happening next.
Improvements
I definitely want to improve the getProjectBranchWithFileInfo code so that duplication is removed. But before I do that, I want to retroactively write tests for the method so that I can quickly and automatically check I haven’t broken the code when I refactor it.
These are the most immediate improvements I can think of, but I’m sure others with emerge.
Prototyping post
To put all of this in context and explain why it was so critical for me to get this functionality in place without writing all the tests I should have, I need to write another post.
So the next post I write on HitherContent is going to be about the rapid prototyping itself, how it’s done and why we’re doing it. And it’ll probably be a bit less technical and more about the content model we’re following.
With thanks
Thanks to Ben, Pete and Ricardo at GatherContent for helping me understand how the GatherContent API processes files a bit better.
I hope describing this process proves useful to anybody thinking of doing something similar or thinking of using my HitherContent package for themselves.